
Project 2: Curriculum Learning applied in RL simulation complexity to lighten and speed up an agent’s training time.
Curriculum Complexity: A Framework for Computationally Efficient Reinforcement Learning Control of Soft Robotic Agents
Overview
This project presents a framework for reducing the computational expense associated with controlling soft robotic agents using reinforcement learning. While there has been significant research on controlling rigid robotic arms, the control of soft robots, particularly through machine learning methods, remains an underexplored area. This thesis proposes an online reinforcement learning approach aimed at effectively controlling soft robots while minimizing computational costs.
Key Objectives
- Reduce Computational Expense: Develop methods to lower the computational burden for controlling soft robots with infinite degrees of freedom (DOF).
- Curriculum Learning: Leverage curriculum learning to train reinforcement learning policies on low-fidelity systems and gradually increase fidelity.
- Framework Development: Create a framework, Complexity Curriculum, to train soft robotic agents efficiently using SoMoGym environments.
Methodology
- SoMoGym Environments: Utilize the SoMoGym toolkit to simulate and train controllers for soft robots in environments like Planar Reaching and Block Pushing.
- Curriculum Learning: Apply curriculum learning by training agents on tasks of increasing complexity, represented by the number of segments per actuator in the soft robot simulation.
- PPO Algorithm: Implement Proximal Policy Optimization (PPO) to train the reinforcement learning policies, balancing exploration and exploitation to optimize learning.
Experiments
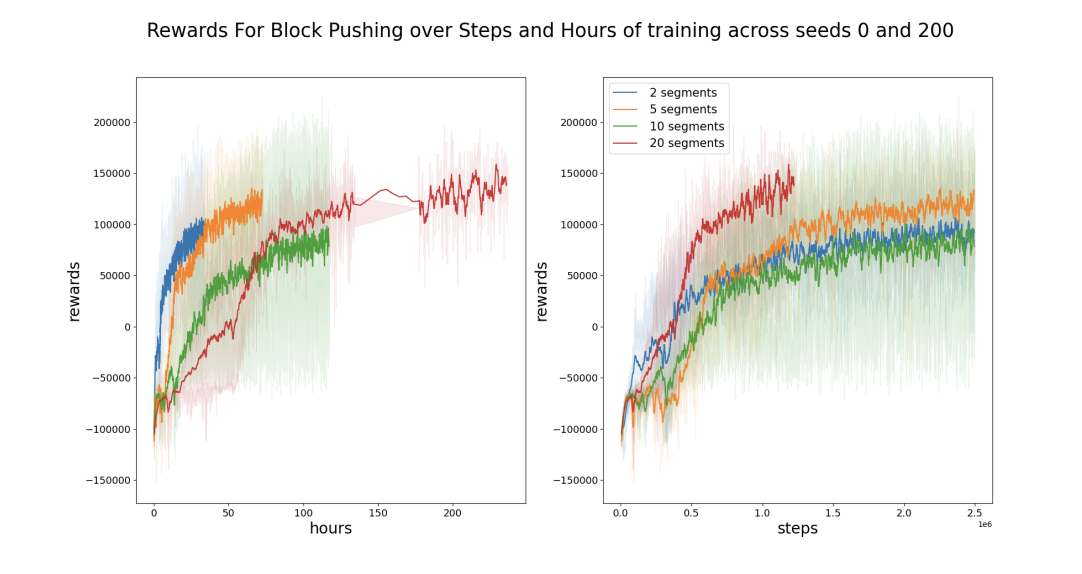
Baseline Experiments
- Planar Reaching: Trained agents with 2, 5, 10, and 20 segments per actuator to observe the impact of discretization on training time and learned behaviors.
- Block Pushing: Conducted similar experiments with 2, 5, 10, and 20 segments per actuator, noting the differences in training duration and performance.
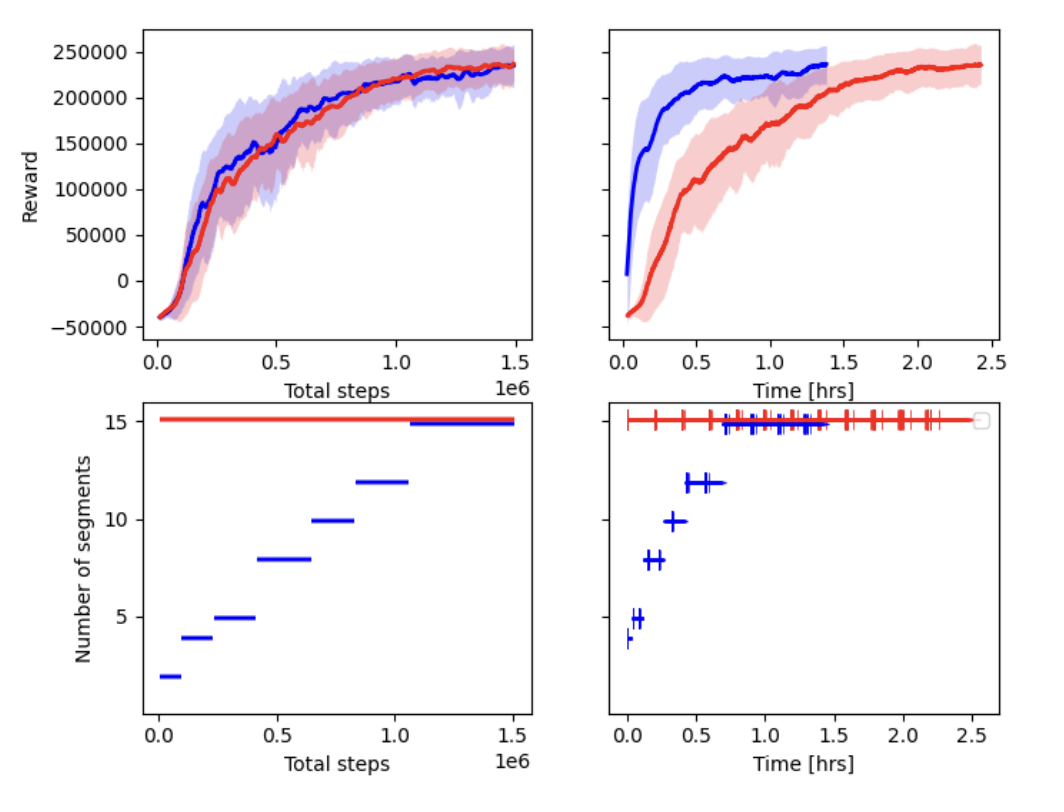
Curriculum Complexity
- Planar Reaching: Implemented curriculum learning over 2, 4, 5, 8, 10, and 15 segments per actuator, demonstrating faster convergence and higher rewards compared to static high-fidelity training.
- Block Pushing: Applied curriculum learning to train agents from 2 to 10 segments per actuator, achieving efficient training despite higher variance due to interaction with the environment.
Findings
- Training Efficiency: Curriculum learning significantly reduced training time while maintaining high fidelity in learned behaviors.
- Performance Improvement: Agents trained using curriculum learning achieved comparable or better performance than those trained directly on high-fidelity simulations.
Conclusion
This framework demonstrates the potential of curriculum learning in enhancing the efficiency and effectiveness of reinforcement learning for soft robotic control. By gradually increasing task complexity, the computational burden is reduced, paving the way for more advanced and practical applications of soft robotics in various fields.
Repository and Resources
To read the full analysis, you can download the PDF file.