
Project 1: GPT2 Finetuning
Fine-tuning GPT-2 for Dictionary-based Language Generation
Overview
This project explores the fine-tuning of the GPT-2 model using Wiktionary data to enhance its ability to generate dictionary-style content. The goal is to adapt GPT-2 to model the relationship between words, definitions, and example usages effectively. The following sections detail the methodology, including key mathematical concepts used in the model architecture and evaluation.
Introduction to GPT-2
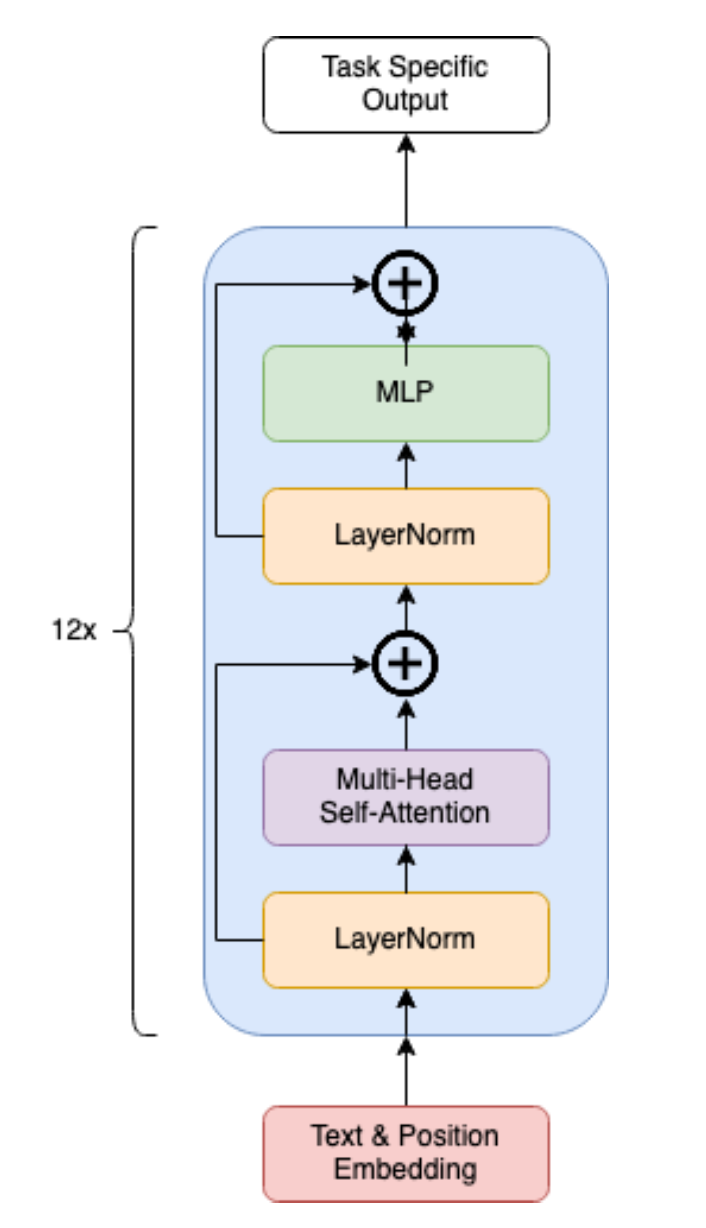
GPT-2 is a unidirectional, causal language model pre-trained on a diverse dataset obtained from the internet. The core architecture of GPT-2 is based on the Transformer model, which employs self-attention mechanisms to process text sequences. The model architecture includes the following key components:
- Input Representation:
- The input sequence is tokenized into sub-word pieces using Byte-Pair Encoding (BPE).
- Positional embeddings are added to token embeddings to encode the position of each token in the sequence.
Mathematically, this can be represented as:
\[ h_0 = \text{Dropout}(U W_e + W_p) \]
where \(W_e\) is the token embedding matrix, \(W_p\) is the positional embedding matrix, and \(U\) is the one-hot encoded sequence.
- Transformer Blocks:
- Each Transformer block consists of a multi-head self-attention mechanism followed by a position-wise feed-forward network.
- Layer normalization and residual connections are applied to stabilize and improve the training dynamics.
The operations within a Transformer block can be expressed as:
\[ \hat{h}_i = \text{Multi-Head Self-Attn}(\text{LayerNorm}(h_i)) \] \[ g_i = h_i + \hat{h}_i \] \[ \hat{g}_i = \text{MLP}(\text{LayerNorm}(g_i)) \] \[ h_{i+1} = g_i + \hat{g}_i \]
- Self-Attention Mechanism:
- Self-attention calculates attention weights based on the similarity between query and key vectors, and these weights are used to compute a weighted sum of the value vectors.
The self-attention operation is defined as:
\[ \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{Q K^T}{\sqrt{d}}\right) V \]
where \(Q\), \(K\), and \(V\) are the query, key, and value matrices, respectively, and \(d\) is the dimensionality of the key vectors.
- Model Architecture:
As discussed in the project documentation, GPT-2 uses a Transformer decoder architecture. A high-level visualization of the Transformer architecture for GPT-2 is as follows:
\[ h_0 = \text{Dropout}(U W_e + W_p) \] \[ h_i = \text{TransformerBlock}(h_{i-1}), \quad i \in [1, n] \] \[ \hat{h}_n = \text{LayerNorm}(h_n) \] \[ P(x) = \text{Softmax}(\hat{h}_n W_e^T) \]
where \(W_e \in \mathbb{R}^{|V| \times d}\) is the token embedding, \(W_p \in \mathbb{R}^{k \times d}\) is the positional embedding, \(U \in \mathbb{Z}^{k \times |V|}\) consists of the one-hot encoded sequence of \(k\) symbols, \(n = 12\) is the number of repeated Transformer blocks within the network, and \(P(x)\) represents the probability distribution the network generates over the next potential token.
Model Tuning and Evaluation
The tuning process involved fine-tuning GPT-2 on a dataset extracted from Wiktionary. The dataset consists of words, their definitions, and example usages. The fine-tuning procedure included the following steps:
- Dataset Preparation:
- The dataset was split into training, validation, and test sets.
- Two versions of the dataset were created: Forward (word precedes definition/example) and Reverse (definition/example precedes word).
- Tuning Procedure:
- GPT-2 was initialized with pre-trained weights and fine-tuned using the AdamW optimizer with specific hyperparameters.
- The model was evaluated on the validation set at regular intervals to prevent overfitting.
- Cosine Similarity for Evaluation:
- Cosine similarity was used to evaluate the similarity between generated and actual embeddings.
The cosine similarity between two vectors \(\vec{x}\) and \(\vec{y}\) is defined as:
\[ \text{cosine similarity} = \frac{\vec{x} \cdot \vec{y}}{\|\vec{x}\|_2 \|\vec{y}\|_2} = \frac{\sum_{i=1}^{n} x_i \cdot y_i}{\sqrt{\sum_{i=1}^{n} x_i^2} \sqrt{\sum_{i=1}^{n} y_i^2}} \]
On the flip side, the cosine distance is defined as:
\[ \text{cosine distance} = 1 - \text{cosine similarity} \]
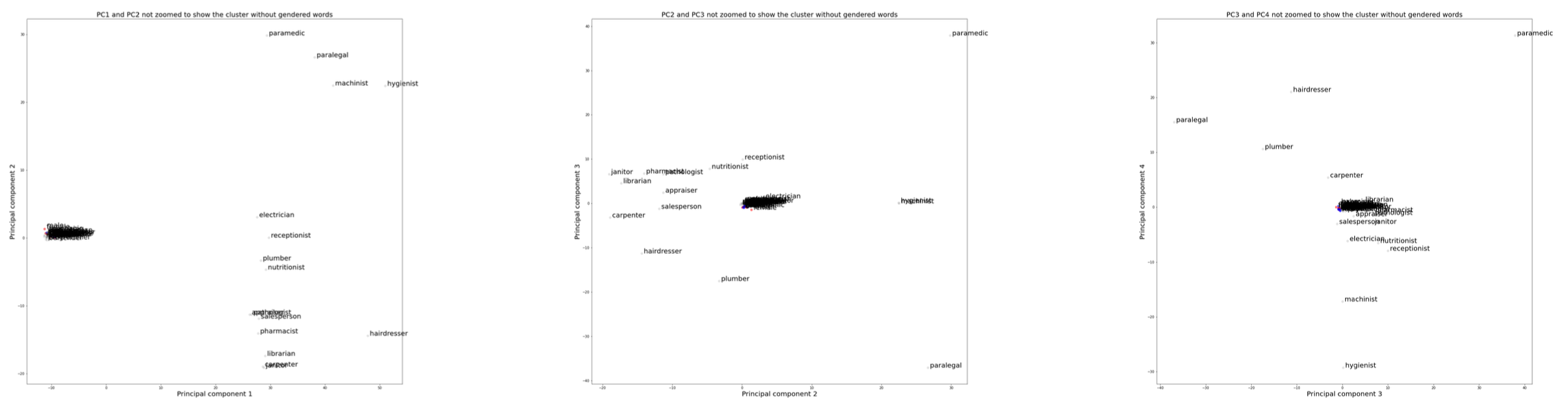
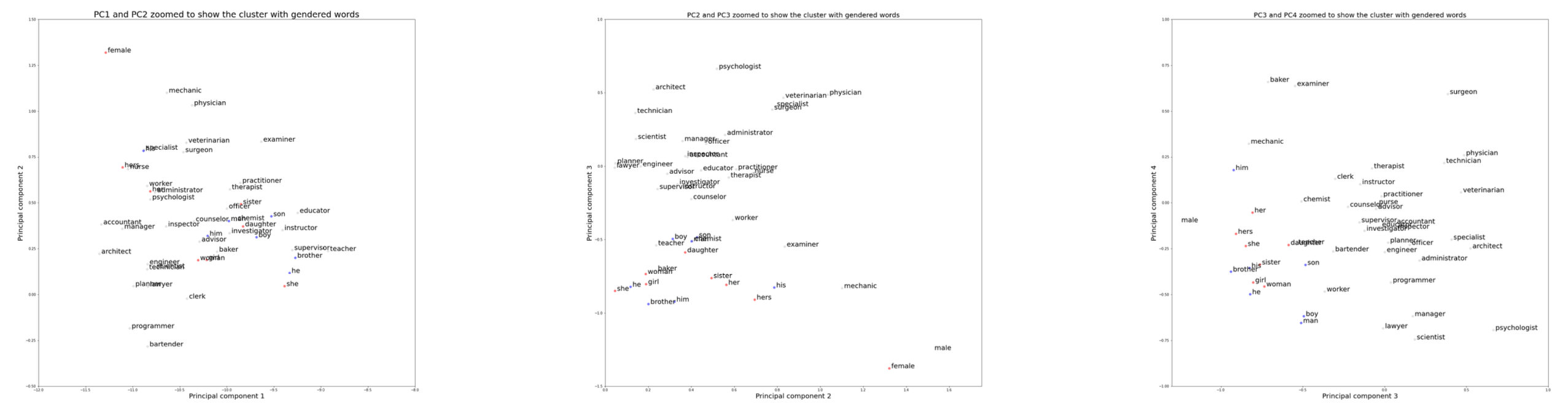
Findings
- The fine-tuned GPT-2 model demonstrated effective generation of definitions and example usages.
- The evaluation using cosine similarity showed that the generated embeddings closely matched the actual embeddings.
Conclusion
This project successfully fine-tuned the GPT-2 model for dictionary-based language generation. The use of self-attention mechanisms and Transformer architecture allowed the model to capture complex relationships between words, definitions, and usages.
Repository and Resources
For more details and access to the code, please visit the GitHub Repository.
To read the full analysis, you can download the PDF file.